The rise of Large Language Models (LLMs) has transformed how software interacts with information. However, modern AI systems are no longer defined solely by the size of their models, but by how intelligently they retrieve, filter, understand, and reason over data before generating answers.
This evolution has given birth to a new architecture pattern: Agentic RAG + Hybrid Search + Reranking.
Today, this approach is rapidly becoming the new standard for enterprise AI because it delivers significantly more accurate, contextual, scalable, and trustworthy results than traditional Retrieval-Augmented Generation (RAG) systems.
From Traditional RAG to Agentic RAG
The first generation of RAG systems followed a relatively simple workflow:
User Question
→ Retrieve Relevant Documents
→ Send Context to LLM
→ Generate AnswerWhile effective for simple document-based chatbots, traditional RAG architectures began to show limitations as datasets and reasoning complexity increased.
Common challenges included:
inaccurate retrieval results
irrelevant context injection
weak understanding of user intent
high hallucination rates
inability to dynamically select the best information sources
To solve these limitations, the industry is now moving toward Agentic RAG.
What is Agentic RAG?
Agentic RAG is an advanced evolution of Retrieval-Augmented Generation where AI agents orchestrate the retrieval and reasoning process dynamically.
Instead of relying on static vector search alone, the system can:
understand user intent
choose optimal retrieval strategies
combine multiple knowledge sources
perform reasoning before retrieval
refine search queries dynamically
validate whether retrieved context is sufficient
In other words, retrieval becomes an intelligent decision-making process rather than a simple database lookup.
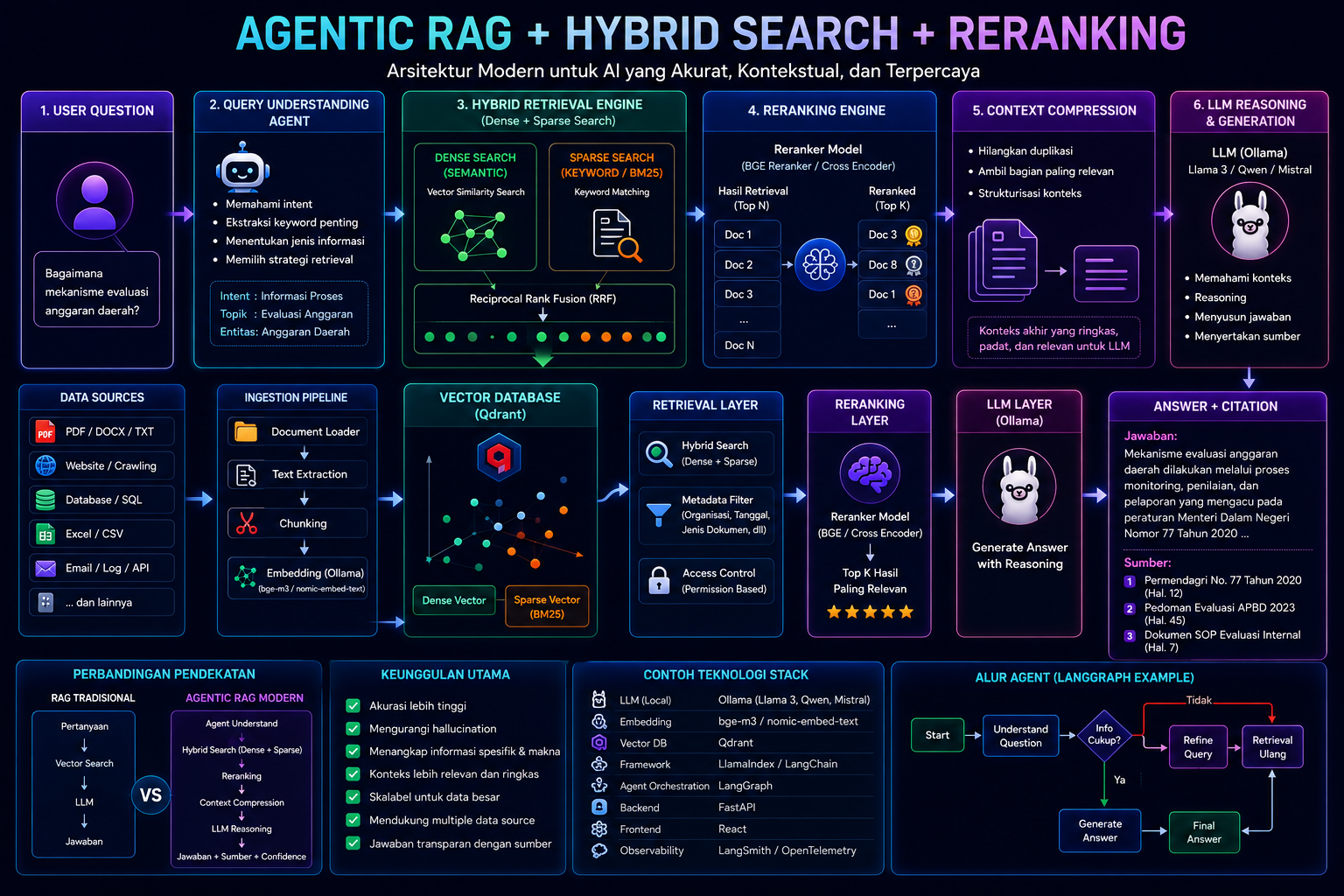
Modern Agentic RAG Architecture
A modern pipeline typically looks like this:
User Question
↓
Query Understanding Agent
↓
Hybrid Retrieval Engine
(Dense + Sparse Search)
↓
Reranking Engine
↓
Context Compression
↓
LLM Reasoning
↓
Final Answer + CitationThis architecture combines several cutting-edge AI techniques into a unified intelligent system.
Hybrid Search: Combining Semantic and Keyword Retrieval
One major weakness of pure vector search is that it often struggles with highly specific terms such as:
document IDs
regulation numbers
system codes
abbreviations
technical terminology
To overcome this limitation, modern systems use Hybrid Search, which combines:
Dense Retrieval (Semantic Search)
Dense retrieval uses embeddings to understand the meaning and semantic relationships between sentences.
For example:
“How does regional budget evaluation work?”can retrieve documents discussing:
“monitoring and assessment mechanisms for regional financial management”even if the wording is completely different.
Sparse Retrieval (Keyword / BM25 Search)
Sparse retrieval uses traditional keyword-based search methods.
It is highly effective for:
exact matching
identifiers
regulation numbers
filenames
specific terminologies
Why Hybrid Search Matters
Hybrid search combines the strengths of both approaches:
Semantic IntelligenceExact Keyword Matchingunderstands contextunderstands exact identifiersflexibleprecisenatural language friendlyenterprise-data friendly
The result is significantly more reliable enterprise-grade AI retrieval.
Reranking: Filtering the Best Context
After retrieval, the system may still return dozens of potentially relevant documents.
However, not all retrieved chunks are equally useful.
This is where Reranking Models become critical.
A reranker:
re-evaluates retrieved results
measures actual relevance
reorders retrieved documents
selects the best context for the LLM
Without reranking, LLMs often receive noisy or partially relevant context.
With reranking:
accuracy improves dramatically
hallucinations decrease
prompts become more efficient
answers become more focused
Popular reranking models today include:
BAAI BGE Reranker
Cohere Rerank
Jina Reranker
Cross Encoder Models
Why This Architecture is Becoming the New Standard
Modern enterprise AI systems require much more than simple chat capabilities.
They need:
1. High Accuracy
AI systems must generate responses grounded in trusted data rather than probabilistic assumptions alone.
2. Scalability
Enterprise environments may contain millions of documents distributed across multiple systems.
Traditional RAG pipelines struggle at this scale.
3. Explainability
Organizations increasingly require AI systems to provide citations and transparent reasoning.
4. Multi-Source Intelligence
Modern AI systems need to integrate data from:
PDFs
APIs
databases
spreadsheets
emails
logs
knowledge bases
5. Dynamic Reasoning
AI should determine what information needs to be retrieved instead of relying solely on static retrieval pipelines.
Technologies Powering Modern Agentic RAG
A modern AI stack commonly includes:
LayerTechnologiesLLMLlama 3, Qwen, MistralLocal InferenceOllamaVector DatabaseQdrantRetrieval FrameworkLlamaIndex / LangChainAgent WorkflowLangGraphBackend APIFastAPIFrontendReactObservabilityLangSmith / OpenTelemetry
The Role of Ollama in Modern AI Infrastructure
Ollama has become increasingly popular because it enables organizations to run powerful LLMs locally and privately.
Key advantages include:
lower inference costs
improved privacy
lower latency
simplified deployment
enterprise-friendly local AI infrastructure
Ollama is now widely used for:
local LLM inference
embeddings
RAG pipelines
AI agents
private enterprise AI systems
Beyond RAG: The Future of AI-Native Systems
Agentic RAG represents only the beginning of a broader transformation toward AI-Native Architecture.
Future systems will evolve into:
autonomous retrieval systems
memory-driven AI
self-improving agents
multi-agent collaboration platforms
reasoning-first infrastructures
In this future, AI will no longer function merely as a chatbot, but as a dynamic intelligence layer capable of understanding, retrieving, reasoning, evaluating, and acting autonomously.
Conclusion
Agentic RAG + Hybrid Search + Reranking is redefining the foundation of modern AI systems.
This architecture transforms traditional RAG from a simple “search-and-generate” pipeline into a sophisticated reasoning-driven intelligence system capable of delivering:
more accurate retrieval
stronger contextual understanding
reduced hallucinations
scalable enterprise search
transparent AI responses
and significantly more trustworthy outputs
As organizations move toward AI-native infrastructures, this architecture will likely become the core foundation powering the next generation of intelligent enterprise systems.