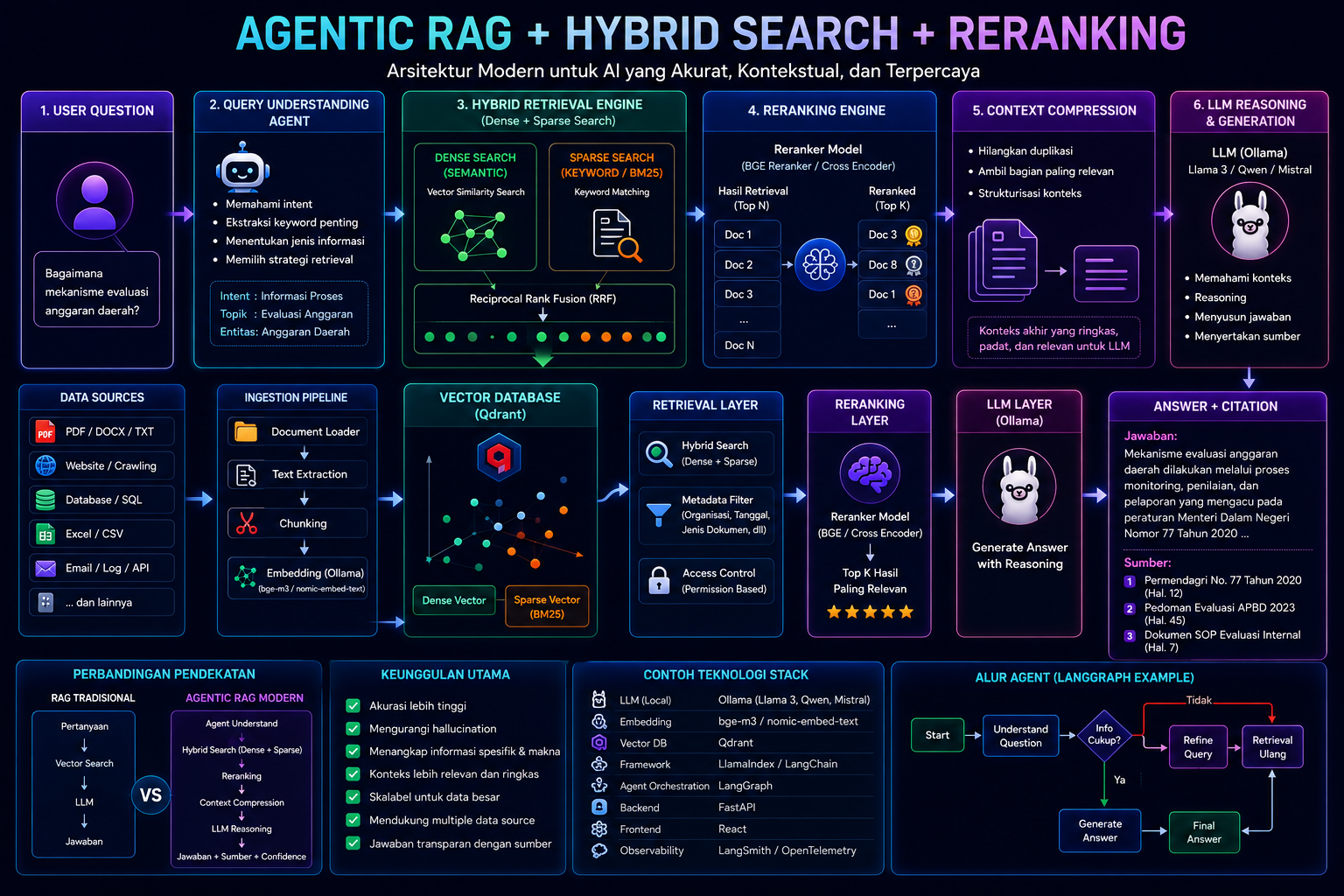
Di era Large Language Model (LLM), kemampuan AI tidak lagi hanya bergantung pada seberapa besar model yang digunakan, tetapi juga pada bagaimana sistem tersebut mencari, memahami, dan menyusun informasi sebelum menghasilkan jawaban. Di sinilah muncul evolusi terbaru dari teknologi Retrieval-Augmented Generation (RAG): Agentic RAG + Hybrid Search + Reranking.
Pendekatan ini mulai menjadi standar baru dalam pembangunan sistem AI modern karena mampu menghadirkan jawaban yang jauh lebih akurat, kontekstual, dan dapat dipercaya dibandingkan arsitektur RAG generasi awal.
Dari RAG Tradisional ke Agentic RAG
Pada generasi pertama, sistem RAG bekerja dengan alur sederhana:
Pertanyaan User
→ Cari dokumen relevan
→ Kirim konteks ke LLM
→ Generate jawabanPendekatan ini cukup efektif untuk chatbot dokumen sederhana. Namun ketika skala data semakin besar dan kebutuhan reasoning semakin kompleks, RAG tradisional mulai memiliki banyak kelemahan:
Retrieval sering tidak akurat
Sulit memahami maksud pertanyaan kompleks
Banyak konteks tidak relevan masuk ke prompt
Hallucination masih tinggi
Tidak mampu memilih sumber terbaik secara dinamis
Karena itulah lahir konsep Agentic RAG.
Apa Itu Agentic RAG?
Agentic RAG adalah evolusi RAG yang menggunakan AI Agent sebagai pengatur proses retrieval dan reasoning.
Alih-alih hanya melakukan pencarian vector biasa, sistem kini mampu:
Memahami intent pertanyaan
Memilih strategi pencarian terbaik
Menggabungkan beberapa sumber data
Melakukan reasoning sebelum retrieval
Menentukan konteks mana yang paling relevan
Melakukan iterasi pencarian jika jawaban belum cukup
Dengan kata lain, retrieval tidak lagi statis, tetapi menjadi proses yang “cerdas” dan adaptif.
Arsitektur Modern Agentic RAG
Pipeline modern umumnya terlihat seperti ini:
User Question
↓
Query Understanding Agent
↓
Hybrid Retrieval Engine
(Dense + Sparse Search)
↓
Reranking Engine
↓
Context Compression
↓
LLM Reasoning
↓
Final Answer + CitationSistem ini menggabungkan beberapa teknologi penting sekaligus.
Hybrid Search: Menggabungkan Semantic dan Keyword Search
Salah satu kelemahan vector search murni adalah AI terkadang gagal menemukan kata-kata spesifik seperti:
nomor dokumen
kode regulasi
nama sistem
istilah teknis
singkatan internal
Karena itu sistem modern menggunakan Hybrid Search, yaitu kombinasi:
Dense Retrieval (Semantic Search)
Menggunakan embedding vector untuk memahami makna kalimat.
Contoh:
“bagaimana mekanisme evaluasi anggaran daerah”dapat menemukan dokumen yang membahas:
“proses monitoring dan penilaian APBD”meskipun kata-katanya berbeda.
Sparse Retrieval (Keyword/BM25 Search)
Menggunakan pencarian keyword tradisional.
Sangat efektif untuk:
kode unik
nama file
nomor surat
istilah spesifik
exact matching
Mengapa Hybrid Search Lebih Baik?
Karena sistem mendapatkan dua kemampuan sekaligus:
Semantic UnderstandingExact Keyword Matchingmemahami konteksmemahami detail spesifikfleksibelpresisinatural languageidentifier-friendly
Hasilnya jauh lebih stabil untuk enterprise AI.
Reranking: Menyaring Hasil Terbaik
Setelah retrieval selesai, biasanya sistem mendapatkan banyak dokumen.
Masalahnya:
tidak semua dokumen benar-benar relevan.
Di sinilah Reranking Model bekerja.
Reranker bertugas:
membaca ulang hasil retrieval
menilai relevansi sebenarnya
menyusun ranking ulang
memilih konteks terbaik untuk LLM
Tanpa reranking, LLM sering menerima konteks yang “noise”.
Dengan reranking:
akurasi meningkat
hallucination turun
jawaban lebih fokus
konteks prompt lebih efisien
Model reranker populer saat ini:
BAAI BGE Reranker
Cohere Rerank
Jina Reranker
Cross Encoder Models
Mengapa Arsitektur Ini Menjadi Standar Baru?
Karena enterprise AI modern membutuhkan:
1. Akurasi Tinggi
AI harus menjawab berdasarkan data valid, bukan sekadar probabilitas bahasa.
2. Scalability
Data perusahaan bisa mencapai jutaan dokumen.
RAG biasa mulai kesulitan pada skala besar.
3. Explainability
Sistem harus mampu menunjukkan sumber jawaban.
4. Multi-source Intelligence
AI modern tidak hanya membaca satu database, tetapi:
PDF
email
API
database
spreadsheet
knowledge base
log system
5. Dynamic Reasoning
AI harus mampu menentukan sendiri:
“informasi mana yang perlu dicari.”
Teknologi yang Banyak Digunakan Saat Ini
Stack modern umumnya menggunakan kombinasi berikut:
LayerTeknologiLLMLlama 3, Qwen, MistralLocal InferenceOllamaVector DatabaseQdrantRetrieval FrameworkLlamaIndex / LangChainAgent WorkflowLangGraphBackend APIFastAPIFrontendReactObservabilityLangSmith / OpenTelemetry
Peran Ollama dalam Arsitektur Modern
Ollama menjadi sangat populer karena memungkinkan perusahaan menjalankan LLM secara lokal.
Keuntungan utamanya:
data lebih aman
latency rendah
biaya inference lebih murah
mudah deployment
cocok untuk private enterprise AI
Ollama kini sering digunakan sebagai local inference engine untuk:
embedding
reranking
chat completion
AI agents
RAG pipelines
Masa Depan: Dari RAG Menuju AI-Native Systems
Agentic RAG hanyalah awal.
Ke depan, sistem AI akan berkembang menjadi:
autonomous retrieval systems
self-improving agents
memory-driven AI
multi-agent collaboration
reasoning-first architecture
Artinya, AI tidak lagi hanya “menjawab pertanyaan”, tetapi mulai berperan sebagai sistem yang mampu memahami, mencari, mengevaluasi, dan mengambil keputusan secara mandiri.
Kesimpulan
Agentic RAG + Hybrid Search + Reranking merupakan fondasi baru bagi sistem AI modern.
Pendekatan ini mengubah RAG dari sekadar “search + generate” menjadi sistem reasoning yang jauh lebih cerdas, adaptif, dan enterprise-ready.
Di masa depan, hampir seluruh platform AI enterprise kemungkinan akan mengadopsi pola ini karena mampu menghadirkan:
retrieval yang lebih akurat
reasoning yang lebih baik
konteks yang lebih relevan
jawaban yang lebih terpercaya
dan pengalaman AI yang jauh lebih natural.
Transformasi ini menandai pergeseran besar:
dari sekadar chatbot berbasis LLM menuju ekosistem AI-Native Architecture yang sesungguhnya.