Pendahuluan
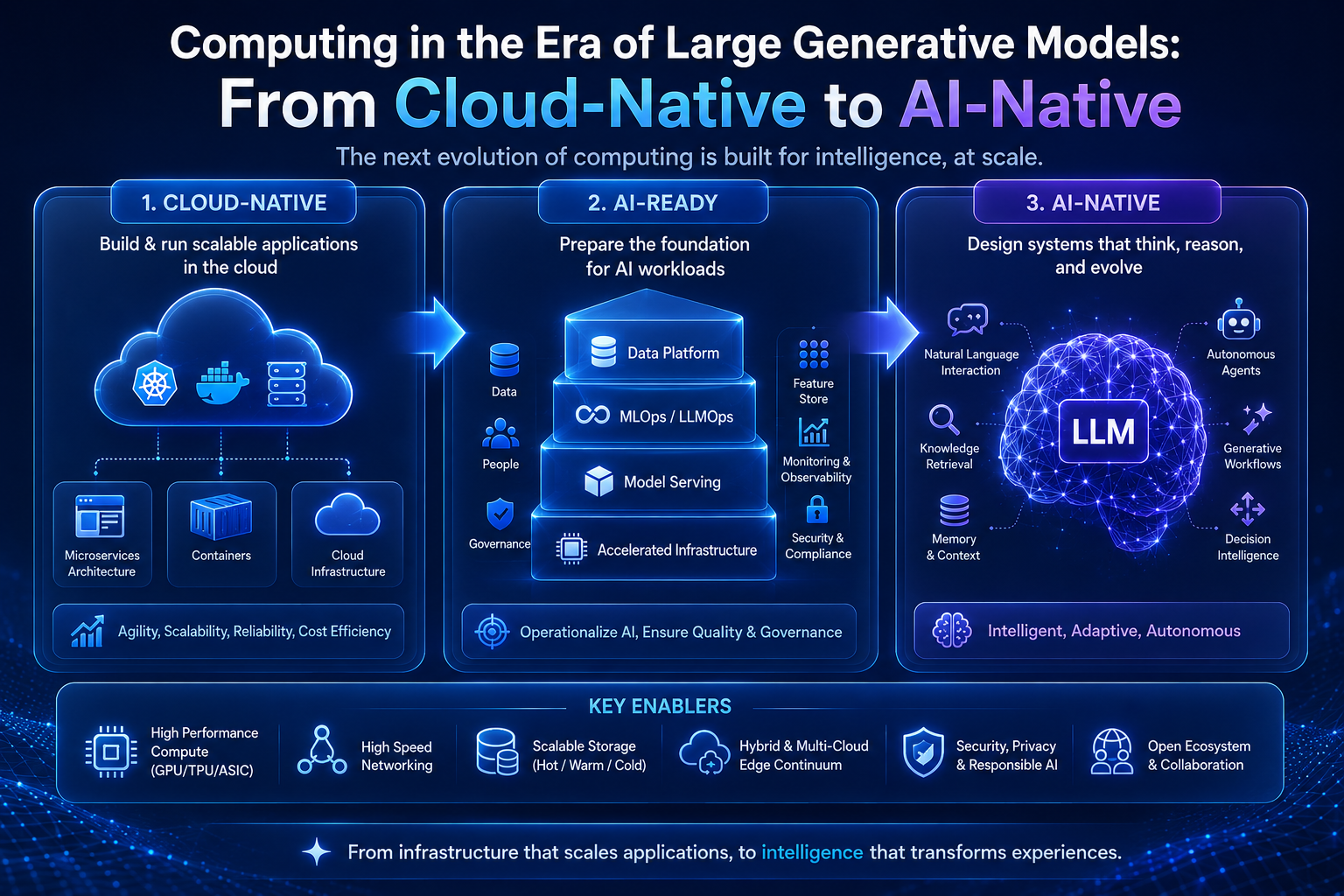
Selama lebih dari satu dekade, paradigma cloud-native computing telah menjadi fondasi bagi sebagian besar aplikasi modern. Arsitektur berbasis kontainer, microservices, dan orkestrasi seperti Kubernetes mengubah cara perangkat lunak dirancang, diterapkan, dan diskalakan. Namun, kemunculan model generatif besar (Large Generative Models/LGM) seperti GPT, Claude, Gemini, dan Llama, dengan miliaran hingga triliunan parameter, menggeser asumsi dasar yang selama ini menopang dunia komputasi awan.
Kita sedang memasuki era baru yang sering disebut sebagai AI-Native Computing: sebuah paradigma di mana model AI bukan lagi sekadar beban kerja tambahan di atas infrastruktur cloud, melainkan menjadi pusat gravitasi yang membentuk ulang setiap lapisan tumpukan teknologi, mulai dari perangkat keras, jaringan, sistem operasi, hingga model pemrograman.
Artikel ini membahas perubahan fundamental yang terjadi, mengapa cloud-native tidak lagi cukup, dan bagaimana arsitektur AI-native akan membentuk masa depan komputasi.
Memahami Era Cloud-Native
Cloud-native computing dirancang untuk dunia di mana beban kerja sebagian besar berupa layanan web, basis data transaksional, dan aplikasi enterprise. Karakteristik utamanya meliputi:
Stateless services yang mudah direplikasi secara horizontal
Microservices yang dipisahkan secara longgar dengan API yang terdefinisi
Container orchestration melalui Kubernetes untuk penjadwalan dan penskalaan
Auto-scaling reaktif berdasarkan metrik CPU, memori, atau permintaan
CPU-centric infrastructure dengan akses memori yang relatif seragam
Model ini sangat efektif untuk aplikasi tradisional. Sebuah situs e-commerce, misalnya, dapat menambah ribuan replika layanan checkout selama periode puncak, lalu menguranginya saat lalu lintas mereda. Beban kerja umumnya bersifat embarrassingly parallel, dengan kebutuhan komunikasi antar-instans yang minimal.
Mengapa Cloud-Native Tidak Cukup untuk Era AI
Beban kerja model generatif besar memiliki karakteristik yang sangat berbeda dari aplikasi web tradisional, dan perbedaan ini melampaui sekadar "membutuhkan lebih banyak GPU". Beberapa benturan mendasar antara LGM dan cloud-native meliputi:
1. Beban Kerja Stateful dan Bersifat Monolitik
Sebuah model dengan ratusan miliar parameter tidak dapat dijalankan pada satu node tunggal. Model harus dipartisi ke puluhan bahkan ratusan GPU melalui tensor parallelism, pipeline parallelism, dan expert parallelism. Ini melanggar asumsi inti cloud-native bahwa instans bersifat stateless dan dapat diganti dengan mudah. Kehilangan satu node dapat memaksa rekonstruksi seluruh runtime model.
2. Komunikasi Bandwidth-Tinggi yang Sinkron
Inference dan training LGM membutuhkan komunikasi all-reduce dan all-to-all dengan latensi mikrodetik dan throughput ratusan GB/detik antar-GPU. Jaringan cloud tradisional yang dirancang untuk lalu lintas TCP utara-selatan tidak memadai. Diperlukan interkoneksi seperti NVLink, NVSwitch, atau InfiniBand RDMA, dengan topologi yang sadar akan lokalitas (rack-aware, zone-aware).
3. Kebutuhan Memori yang Ekstrem dan KV-Cache
Selama proses inference, Key-Value cache (KV-cache) tumbuh secara linear terhadap panjang konteks dan jumlah pengguna konkuren. Mengelola memori GPU yang terbatas (HBM) dengan ribuan sesi pengguna yang aktif menuntut pendekatan baru: paged attention, prefix caching, disaggregated serving, dan offloading ke memori CPU atau SSD NVMe.
4. Pola Beban yang Sangat Berbeda
Permintaan inference LGM bersifat long-tailed: beberapa permintaan menghasilkan 50 token, yang lain menghasilkan 4.000 token. Penjadwalan berbasis QPS (queries per second) tidak relevan; yang penting adalah time-to-first-token (TTFT), time-per-output-token (TPOT), dan throughput token agregat. Ini menuntut penjadwal yang memahami semantik internal dari proses generasi.
5. Auto-scaling yang Lambat dan Mahal
Memuat model 70B parameter ke GPU dapat memakan waktu beberapa menit. Auto-scaling reaktif ala Kubernetes tidak relevan ketika "cold start" sebuah pod inference adalah 3-5 menit, sementara permintaan pengguna mengharapkan respons dalam hitungan detik.
Karakteristik AI-Native Computing
AI-native computing adalah paradigma di mana seluruh tumpukan dirancang dari awal dengan mempertimbangkan beban kerja AI sebagai first-class citizen. Beberapa pilar utamanya:
Heterogenitas sebagai Default
Infrastruktur AI-native bukan sekadar "cloud + GPU". Ia memadukan CPU, GPU, TPU, NPU, FPGA, akselerator inference khusus (seperti AWS Inferentia atau Groq LPU), dan perangkat keras pengelolaan memori seperti CXL. Sistem operasi dan penjadwal harus mampu menempatkan beban kerja pada jenis perangkat keras yang tepat secara dinamis.
Penjadwalan Sadar-Model dan Sadar-Topologi
Penjadwal AI-native tidak lagi hanya melihat "request berapa CPU dan memori". Ia memahami:
Ukuran model dan kebutuhan partisi
Topologi interkoneksi (NVLink island, rack, zone)
Profil komputasi prefill vs decode
Reusabilitas KV-cache antar permintaan
Prioritas dan SLA per pengguna atau aplikasi
Sistem seperti vLLM, SGLang, TensorRT-LLM, dan Triton Inference Server bersama dengan orkestrator seperti KServe dan Ray Serve mulai mewujudkan visi ini.
Disaggregated Architecture
Pemisahan fungsi menjadi tren dominan: prefill (komputasi-berat) dipisahkan dari decode (memori-berat), KV-cache disimpan di tier memori berbeda (HBM, DRAM, NVMe), dan komputasi dipisahkan dari penyimpanan parameter. Ini memungkinkan setiap komponen diskalakan dan dioptimalkan secara independen.
Continuous Batching dan Speculative Execution
Berbeda dengan static batching tradisional, AI-native serving menggunakan continuous batching di mana permintaan baru dapat bergabung dan keluar dari batch pada setiap langkah generasi. Speculative decoding menggunakan model kecil untuk menebak token, lalu memvalidasinya dengan model besar, melipatgandakan throughput tanpa mengubah hasil.
Observability untuk Beban Kerja Probabilistik
Aplikasi cloud-native dipantau melalui metrik deterministik: latensi, error rate, throughput. Aplikasi AI-native membutuhkan dimensi baru: kualitas output, halusinasi, drift distribusi, biaya per token, panjang konteks rata-rata, hit rate prefix cache, dan utilisasi tensor core. Observability AI-native (LLMOps) menjadi disiplin tersendiri.
Perbandingan Paradigma
DimensiCloud-NativeAI-NativeUnit komputasiContainer/PodReplika model + KV-cachePerangkat keras dominanCPU, memori DRAMGPU/TPU, HBM, NVLinkPola komunikasiREST/gRPC utara-selatanCollective ops timur-baratPenyimpanan stateDatabase eksternalKV-cache + parameter di GPUAuto-scalingDetik, reaktifMenit, prediktif, model-awareGranularitas bebanRequestTokenMetrik utamaQPS, latensi p99TTFT, TPOT, token/detik, kualitasOptimasi biayaRight-sizing CPUQuantization, batching, caching
Tantangan Teknis yang Membentuk Masa Depan
Manajemen Memori GPU
HBM adalah sumber daya yang langka dan mahal. Inovasi seperti PagedAttention (vLLM), FlashAttention, KV-cache quantization, dan offloading hierarkis akan terus berkembang. Standar seperti CXL 3.0 berpotensi mengubah cara memori dibagi antar akselerator.
Inference yang Hemat Energi
Sebuah pusat data AI dapat mengonsumsi puluhan hingga ratusan megawatt. Teknik seperti quantization (INT8, INT4, FP4), pruning, distillation, MoE (Mixture of Experts), dan inference adaptif menjadi krusial bukan hanya untuk biaya, tetapi juga untuk keberlanjutan.
Multi-Tenancy yang Aman
Bagaimana melayani ribuan pelanggan pada satu cluster GPU tanpa bocornya KV-cache, prompt, atau output antar tenant? Isolasi pada level perangkat keras (MIG di NVIDIA), enkripsi memori, dan confidential computing untuk GPU adalah area penelitian aktif.
Edge dan On-Device AI
Tidak semua inference akan terjadi di pusat data. Model yang dikuantisasi dan didistilasi akan berjalan di laptop, ponsel, dan perangkat IoT. AI-native computing mencakup spektrum dari hyperscale data center hingga NPU di chip ponsel, dengan orkestrasi hibrida antar tier.
Programming Model Baru
Kerangka kerja seperti PyTorch, JAX, Triton, dan Mojo terus berkembang untuk menjembatani produktivitas pengembang dengan performa perangkat keras. Compiler AI seperti XLA, TVM, dan MLIR menjadi lapisan fundamental yang setara dengan compiler bahasa pemrograman tradisional.
Implikasi bagi Pengembang dan Organisasi
Transisi ini bukan sekadar pertanyaan teknis; ia menggeser bagaimana tim direkrut, dilatih, dan diorganisir. Beberapa implikasi praktis:
Peran baru: Insinyur ML platform, spesialis inference optimization, dan LLMOps engineer menjadi kebutuhan kritis di samping DevOps tradisional.
Reorientasi biaya: Anggaran infrastruktur bergeser dari "CPU-jam" ke "GPU-jam", dan optimasi biaya per token menjadi metrik bisnis utama.
Vendor lock-in baru: Ketergantungan pada CUDA, ekosistem NVIDIA, atau API model proprietary menciptakan dimensi lock-in yang berbeda dari era cloud-native.
Arsitektur aplikasi: Pola seperti RAG (Retrieval-Augmented Generation), agentic workflows, dan tool use mengubah cara aplikasi dirancang. Aplikasi tidak lagi memanggil API yang deterministik, tetapi mengkoordinasikan model probabilistik dengan retrieval, memori, dan eksekusi alat.
Keamanan dan tata kelola: Prompt injection, data poisoning, dan kebocoran model adalah ancaman baru yang tidak ada padanan langsungnya di dunia cloud-native.
Apakah Cloud-Native Mati?
Tidak. Cloud-native dan AI-native akan berkoeksistensi dalam jangka panjang. Sebagian besar aplikasi enterprise, sistem transaksional, dan layanan web akan tetap berjalan baik di atas Kubernetes dan microservices. Namun, untuk aplikasi yang berpusat pada AI, paradigma cloud-native akan terlihat seperti fondasi yang diperluas, bukan dipertahankan apa adanya.
Yang paling mungkin terjadi adalah konvergensi: Kubernetes akan terus berevolusi menuju "AI-aware orchestrator" melalui proyek seperti Kubeflow, KServe, Volcano, dan Kueue. Service mesh akan belajar memahami lalu lintas inference. Object storage akan dioptimalkan untuk weights model dan dataset training. Cloud-native akan menyerap pelajaran dari AI-native, sementara AI-native akan meminjam disiplin operasional dari cloud-native.
Kesimpulan
Pergeseran dari cloud-native ke AI-native bukan sekadar tren teknologi; ia adalah transformasi arsitektural yang setara dengan munculnya virtualisasi atau lahirnya cloud computing itu sendiri. Model generatif besar menuntut tumpukan komputasi yang dirancang ulang dari bawah ke atas: perangkat keras heterogen yang sadar akan tensor, jaringan dengan bandwidth ekstrem, sistem memori berlapis, penjadwal yang memahami semantik model, dan model pemrograman yang menjembatani probabilistik dan deterministik.
Bagi organisasi, pertanyaannya bukan lagi "apakah" akan bergerak ke AI-native, tetapi "seberapa cepat" dan "dengan strategi apa". Mereka yang berhasil akan memperlakukan model AI bukan sebagai fitur yang ditempelkan, tetapi sebagai inti dari arsitektur sistem mereka. Dan bagi para insinyur, era ini membuka pintu untuk inovasi paling menarik dalam dekade terakhir: merancang ulang seluruh tumpukan komputasi untuk mendukung kecerdasan dalam skala yang sebelumnya tidak terbayangkan.
Era AI-native baru saja dimulai, dan keputusan arsitektural yang kita buat hari ini akan menentukan bagaimana kecerdasan buatan dilayani, diskalakan, dan diakses oleh miliaran pengguna di tahun-tahun mendatang.